
Breaking Down Machine Learning with Linear Algebra Basics
36 min read A clear primer connecting linear algebra fundamentals—vectors, matrices, eigenvalues, SVD—to core machine learning methods like regression, PCA, and neural networks with intuitive examples, visuals, and practical tips. (0 Reviews)
Machine learning can look like magic until you realize how much of it is just careful bookkeeping with vectors and matrices. Linear algebra is the language underneath model training, prediction, and evaluation. Once you can read shapes, manipulate transformations, and reason about geometry, many ML algorithms become simpler, faster to debug, and far less mysterious.
This article breaks down the core linear algebra ideas that show up in everyday ML practice. You will see actionable tips, worked examples, and mental models that you can plug straight into data analysis, model building, and debugging sessions.
Machine learning through a linear algebra lens
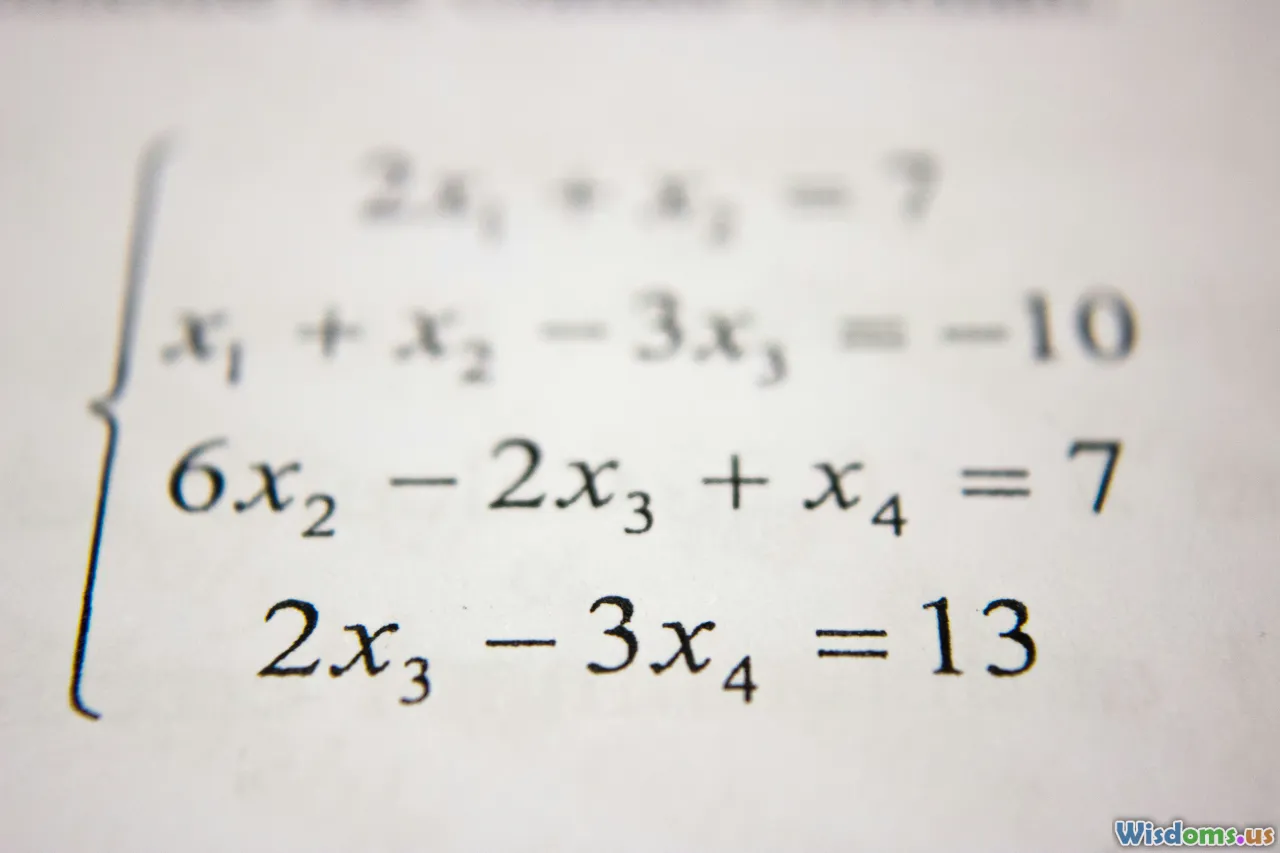
At a high level, supervised learning is about mapping an input vector x to an output y. The word vector is deliberate: most modern data representations are numeric arrays. A batch of inputs is a matrix. A model is a function that maps one array to another, and many such functions can be written as compositions of linear maps plus simple nonlinearities.
Common examples:
- Linear regression: prediction y_hat = X w, with X an n-by-d matrix of n samples and d features, and w a d-by-1 parameter vector.
- Logistic regression: first compute z = X w, then squash elementwise with a sigmoid to get probabilities.
- Neural network layer: h = f(X W + b), where W is d-by-k, b broadcasts over n rows, and f is a nonlinearity.
- PCA: decorrelate data by rotating with orthonormal vectors from an eigendecomposition, then scale by singular values.
When you understand the shapes and the geometry, you see the unifying pattern: stack data into matrices, multiply by parameter matrices, and apply simple nonlinearities. The rest is accounting for errors and constraints, which are also expressed with norms and inner products.
Vectors: data as points, directions, and features

A vector is an ordered list of numbers. In ML, a single example is commonly represented as a column vector x in R^d. The entries might be pixel intensities, TF-IDF scores, sensor measurements, or learned embeddings.
Ways to think about vectors:
- As points: x is a point in a d-dimensional feature space. Distance between points tells you how similar examples are.
- As directions: a parameter vector w points in a direction. Projections of x onto w measure alignment.
- As containers of features: the i-th entry is the weight of feature i. Scaling and combining vectors mixes features in controlled ways.
Simple but essential operations:
- Addition: x + y moves you by y from x. Used for residual updates, gradient steps, and momentum.
- Scalar multiplication: a x stretches or shrinks a vector. Learning rates and regularization coefficients scale updates.
- Elementwise operations: f(x) applied elementwise is core in neural networks and feature transforms, e.g., ReLU(x) = max(0, x).
Concrete example: A flower with features sepal length 5.1, sepal width 3.5, petal length 1.4, petal width 0.2 becomes a 4D vector x = [5.1, 3.5, 1.4, 0.2]^T. A weight vector w defines a score s = w^T x; you can interpret large positive weights as features that push the decision toward one class.
Matrices: stacking examples and modeling transformations

A matrix stacks vectors into rows or columns and represents linear maps. In ML:
- Data matrix X: shape (n, d), n examples, d features.
- Weight matrix W: shape (d, k), mapping d features to k outputs.
- Prediction matrix Y_hat: shape (n, k), with Y_hat = X W.
Why this matters:
- Batch computation: Vectorizing over the batch dimension makes training fast. Compute all predictions at once with matrix multiplication instead of looping over examples.
- Shape discipline: Many bugs come from shape mismatches. Keep row-major conventions consistent: examples-as-rows is a useful default in NumPy and pandas.
- Composition: Two linear layers in a row collapse to one: X W1 W2. This explains why we need nonlinearities between layers; otherwise, the network collapses to a single linear map.
Example: With X in R^{1000 x 50} and W in R^{50 x 10}, computing Y_hat = X W gives 1000 predictions across 10 outputs in a single call to a BLAS-optimized kernel.
The dot product, cosine similarity, and why angle matters

The dot product x dot y = sum_i x_i y_i is at the heart of scoring and similarity.
Key facts:
- Length: ||x||_2 = sqrt(x dot x).
- Projection: x projected onto unit vector u is (x dot u) u.
- Angle: x dot y = ||x|| ||y|| cos(theta). The sign and magnitude reflect alignment.
Cosine similarity uses only the angle: cos_sim(x, y) = (x dot y) / (||x|| ||y||). It is robust to scale differences and widely used in text and embedding search.
Numeric example: For x = [1, 2, 3] and y = [4, 0, 5], x dot y = 14 + 20 + 35 = 19. Norms are ||x|| = sqrt(14), ||y|| = sqrt(41). Cosine similarity is 19 / sqrt(1441) ≈ 19 / 24.0 ≈ 0.79, indicating fairly strong alignment.
In ML pipelines, the dot product powers linear classifiers, attention mechanisms, and similarity search. Optimizing dot products is what BLAS libraries do best, which is why arranging computations into large matrix multiplies pays off.
Norms and distance: measuring error and regularization

A norm measures the size of a vector. In ML you mostly encounter:
- L2 norm: ||x||_2 = sqrt(sum x_i^2). Squared L2 norm sums squared residuals and has smooth derivatives.
- L1 norm: ||x||_1 = sum |x_i|. Promotes sparsity because it penalizes all deviations equally, making many coefficients go exactly to zero under optimization.
Why norms matter:
- Losses: Regression uses L2 residuals, robust regression may use L1, Huber, or quantile losses.
- Regularization: L2 regularization (ridge) shrinks weights toward zero, stabilizing poorly conditioned problems. L1 (lasso) performs feature selection by inducing zeros.
- Geometry: L2 balls are round, L1 balls are diamond-shaped. The corners of the L1 ball align with coordinate axes, explaining why lasso solutions are sparse.
Gradient facts:
- For L(w) = 0.5 ||X w - y||_2^2, grad_w L = X^T (X w - y).
- For L2 regularization with strength lambda, add lambda w to the gradient.
- For L1 regularization, use subgradients: the derivative is sign(w_i) when w_i != 0 and any value in [-1, 1] when w_i = 0.
Linear maps and matrix multiplication: composing layers

A linear map T from R^d to R^k is the operation T(x) = W x for some matrix W. Composition of linear maps corresponds to matrix multiplication: if S(x) = A x and T(x) = B x, then T(S(x)) = B A x.
This simple rule explains major architectural choices:
- Two linear layers without nonlinearity collapse: X W1 W2 is still linear. To get expressive power, you insert a nonlinearity f: X -> f(X W1) W2.
- Parameter count: A linear layer with d inputs and k outputs has d k parameters (plus k biases). Understanding this helps control model size.
- Change of basis: Multiplying by an orthonormal matrix Q rotates or reflects the space without changing distances or dot products. Orthogonality is useful for preserving signal magnitude across layers.
In practice, matrix multiplication is the workhorse in training. Efficient implementations leverage cache-friendly layouts, fused operations, and low-precision arithmetic where stability permits.
Projections and least squares: fitting lines the linear way

Least squares regression finds w minimizing ||X w - y||_2^2. Geometrically, X w is constrained to the column space of X. The best fit is the orthogonal projection of y onto that subspace.
Normal equations: Set gradient to zero to get X^T X w = X^T y. When X^T X is invertible, w = (X^T X)^{-1} X^T y.
Key geometry: The residual r = y - X w is orthogonal to every column of X, i.e., X^T r = 0. This is the condition that characterizes the projection.
Small worked example:
- X = [[1, 0], [0, 1], [1, 1]], y = [1, 2, 3]^T.
- X^T X = [[2, 1], [1, 2]], X^T y = [4, 5]^T.
- Solve [[2, 1], [1, 2]] w = [4, 5]. Inverse is (1/3) [[2, -1], [-1, 2]]. So w = (1/3) [[2, -1], [-1, 2]] [4, 5] = [1, 2].
- Predictions X w = [1, 2, 3]^T, a perfect fit because y equals x1 + 2 x2 in this toy dataset.
Practical takeaways:
- When d is small and X is well-conditioned, the normal equations are fine. For numerical stability, prefer a QR decomposition or SVD, especially if features are collinear.
- Solving with QR avoids forming X^T X explicitly and reduces sensitivity to roundoff.
- Center and scale features to improve conditioning. Standardization often doubles as a regularization aid.
Gradients, Jacobians, and backprop: calculus meets linear algebra

Backpropagation is just the chain rule in matrix form. Two key objects:
- Gradient: For scalar loss L, grad_x L has the same shape as x and points in the direction of steepest ascent.
- Jacobian: For vector function f: R^d -> R^k, J_f(x) is a k-by-d matrix with entries partial f_i / partial x_j.
Linear regression gradient derivation:
- L(w) = 0.5 ||X w - y||_2^2 = 0.5 (X w - y)^T (X w - y).
- grad_w L = X^T (X w - y).
Single linear layer with bias and nonlinearity:
- Forward: z = X W + b, h = f(z), L = loss(h).
- Backward: dL/dz = (dL/dh) hadamard f'(z), dL/dW = X^T (dL/dz), dL/db = sum over rows of dL/dz, and dL/dX = (dL/dz) W^T.
- Note the transposes: gradients w.r.t. weights and inputs are computed with the same matrix but transposed, reflecting adjoint maps.
Two-layer chain example:
- h = f1(X W1 + b1), y_hat = f2(h W2 + b2).
- Given g = dL/dy_hat, propagate: g2 = g hadamard f2'(·), dL/dW2 = h^T g2, then g1 = g2 W2^T, apply nonlinearity derivative: g1 = g1 hadamard f1'(·), and finally dL/dW1 = X^T g1.
Implementation tip: Always verify shapes at each step. A correct gradient has the same shape as its parameter and contracts over the batch dimension.
Eigenvalues, eigenvectors, and why stability matters

An eigenvector v of a square matrix A is a nonzero vector such that A v = lambda v, where lambda is the eigenvalue. Eigen-analysis tells you how a linear transformation stretches or contracts space along special directions.
Why ML practitioners care:
- Optimization dynamics: For gradient descent on a quadratic L(x) = 0.5 x^T H x, the Hessian H dictates curvature. Large eigenvalues require smaller learning rates to avoid divergence. The spectral radius of the update map affects stability.
- Recurrent networks: The product of many Jacobians can explode or vanish depending on eigenvalues and singular values. Orthogonal or unitary matrices help maintain gradient norms.
- Covariance matrices: Eigenvectors of the covariance define principal components. Directions with large eigenvalues carry more variance.
Computational note: Power iteration extracts the dominant eigenvector with repeated multiplication and normalization, a useful mental model for how methods like PCA can be implemented at scale without full decompositions.
Singular value decomposition and PCA: compression and denoising

The singular value decomposition factors any matrix X in R^{n x d} as X = U Σ V^T, where:
- U in R^{n x r} and V in R^{d x r} have orthonormal columns, r = rank(X).
- Σ is diagonal with nonnegative singular values σ1 ≥ σ2 ≥ ... ≥ σr.
Key properties:
- Low-rank approximation: The best rank-k approximation (in Frobenius or spectral norm) is X_k = U_k Σ_k V_k^T, keeping only the top k singular values and vectors. This is the Eckart–Young result.
- Energy explained: The fraction of variance captured by k components is sum_{i=1}^k σ_i^2 divided by sum_{i=1}^r σ_i^2.
PCA via SVD:
- Given zero-mean data matrix X (rows are samples), the sample covariance is C = (1/n) X^T X.
- The right singular vectors V are eigenvectors of C; principal components are columns of V.
- Project data to k dimensions with Z = X V_k. Reconstruction is approximately Z V_k^T.
Practical example: Image compression. Stack grayscale image patches as rows in X. Compute SVD and keep k components. Reconstruct with U_k Σ_k V_k^T. You will observe that small k removes high-frequency noise and preserves dominant structure; as k grows, details return. The trade-off is storage cost O(k (n + d)) versus full O(n d).
Implementation tips:
- Always center features before PCA; otherwise, the first component can point toward the mean rather than variation around it.
- Use randomized SVD for large, sparse datasets to approximate top components quickly while controlling accuracy.
- Plot cumulative variance to choose k pragmatically rather than guessing.
Regularization and ill-conditioning: when algebra saves your model

Ill-conditioning happens when X^T X has a large condition number, meaning tiny perturbations in y or X cause large changes in w. This is common when features are redundant or vary across vastly different scales.
Ridge regression solves (X^T X + λ I) w = X^T y. Adding λ I shifts eigenvalues by λ, reducing the condition number and stabilizing inversion. Geometrically, you shrink solutions toward the origin, preferring smaller weights that generalize better.
Effects to know:
- Bias–variance trade-off: Larger λ increases bias but lowers variance. Validation curves typically show a U-shaped test error versus λ.
- Feature scaling: Standardizing features to zero mean and unit variance often reduces conditioning issues and makes a single λ work across features.
- Lasso vs ridge: Lasso can zero out coefficients for interpretability; ridge shares influence across correlated features. Elastic net blends both.
Diagnostic move: Compute the singular values of X. If the smallest σ is close to zero, expect instability. Ridge effectively clamps these small singular values, improving robustness.
Kernels and feature maps: linear models in disguise

A kernel function K(x, x') computes an inner product in a (possibly high-dimensional) feature space without explicitly mapping x. If φ is the feature map, then K(x, x') = φ(x) dot φ(x'). This trick turns linear algorithms into nonlinear ones in the original space.
Practical kernel facts:
- Gram matrix: For n samples, form K in R^{n x n} with K_ij = K(x_i, x_j). Many algorithms depend only on K.
- Common kernels: RBF or Gaussian kernel K(x, x') = exp(-||x - x'||^2 / (2 σ^2)), polynomial kernels K(x, x') = (x dot x' + c)^p.
- SVMs and kernel ridge regression: Solutions are linear combinations of training examples in feature space, expressed using K.
Example intuition: On a 1D dataset where classes interleave along the line, no linear separator exists. The RBF kernel implicitly maps points into an infinite-dimensional space where similarity decays with distance, allowing a hyperplane to separate classes by leveraging locality.
Scaling note: Kernel methods require O(n^2) storage and O(n^3) time for naive solves. For large n, use approximations such as Nyström or random Fourier features that construct explicit low-dimensional φ(x) approximations.
Probabilistic view: Gaussians, covariance, and whitening

Many ML models assume or converge to Gaussian-like structure. Linear algebra turns those assumptions into concrete operations.
Covariance:
- For zero-mean data, Σ = E[x x^T]. Empirically, Σ ≈ (1/n) X^T X when rows of X are samples.
- Σ is symmetric positive semidefinite. Its eigenvectors give uncorrelated directions, and eigenvalues encode variances along those axes.
Whitening:
- Goal: Transform data to have identity covariance. If Σ = Q Λ Q^T, then x_white = Λ^{-1/2} Q^T x has Cov[x_white] ≈ I.
- In practice: Estimate Σ from data, compute its eigendecomposition or SVD, and apply the transform. Whitening is used before ICA, as a preprocessing step for decorrelation, and in some contrastive learning setups.
Mahalanobis distance:
- For covariance Σ, d(x, μ) = sqrt((x - μ)^T Σ^{-1} (x - μ)). This scales distances by variance and correlation structure, improving anomaly detection and clustering in anisotropic data.
Practical tips: shapes, broadcasting, and numerical hygiene

Even a small improvement in numerical habits and shape literacy pays big dividends in model stability and speed.
Shape and broadcasting discipline:
- Keep a diagram of shapes for each layer. In code, assert expected shapes for tensors.
- Prefer examples-as-rows with shape (n, d); keep weights as (d, k). This aligns with X^T (n, d) and batch matrix multiplies.
- Be explicit about row vs column vectors. A 1D array might behave differently than a 2D array with shape (n, 1).
Stable computations:
- Softmax: For z in R^k, compute softmax(z)_i = exp(z_i - max(z)) / sum_j exp(z_j - max(z)). Subtracting the maximum avoids overflow.
- Log-sum-exp: Use logsumexp to compute log sum_j exp(z_j) stably.
- Normal equations: If you must compute (X^T X)^{-1} X^T y, prefer solving the linear system with a solver rather than explicitly inverting.
- Data scaling: Standardize features and consider mean-centering targets in regression for faster convergence.
Performance:
- Vectorize: Replace Python loops with BLAS-backed operations. Use einsum to make contraction patterns explicit.
- Mixed precision: Use float16 or bfloat16 for multiplications where supported, but keep accumulations and sensitive operations in float32 or float64.
- Sparse: When X is sparse, use sparse-dense multiplies rather than materializing dense arrays.
Debugging strategy:
- Start with tiny dimensions and a controlled seed. Check that forward and backward signals have reasonable magnitudes.
- Compute finite-difference gradients for a handful of parameters to verify analytic gradients.
- Track condition numbers or singular values if you see instability.
Worked example: from data to model with linear algebra

Suppose you want to predict housing prices from two features: square footage and age of the house. You collect 6 examples and store them as rows in X_raw, with y the prices in thousands.
X_raw = [ [1400, 5], [1600, 7], [1700, 15], [1875, 10], [1100, 20], [1550, 12] ]
y = [240, 270, 275, 300, 200, 265]^T
Step 1. Standardize features
- Compute column means and standard deviations. Let μ ≈ [1537.5, 11.5], σ ≈ [250.2, 5.4] (illustrative numbers).
- Transform X = (X_raw - μ) / σ so both features have comparable scales. This improves conditioning of X^T X.
Step 2. Add a bias term
- Create X_bar by concatenating a column of ones: X_bar in R^{6 x 3}. The model is y ≈ X_bar w_bar, where w_bar contains bias and weights.
Step 3. Solve with least squares
- Compute w_bar by QR or SVD. Conceptually, solve X_bar^T X_bar w_bar = X_bar^T y. Let the solution be w_bar = [b, w1, w2]^T.
- Interpretation: w1 is the price change per standard deviation of square footage, w2 per standard deviation of age (likely negative).
Step 4. Inspect conditioning and regularize if needed
- Compute singular values σ1 ≥ σ2 ≥ σ3 of X_bar. If σ3 is much smaller than σ1, try ridge: solve (X_bar^T X_bar + λ I) w_bar = X_bar^T y.
- Choose λ via cross-validation; for tiny datasets, use leave-one-out.
Step 5. Verify with gradient descent
- Initialize w_bar_0 = 0. Iterate w_{t+1} = w_t - η X_bar^T (X_bar w_t - y) / n. Use small η (e.g., 0.1 after normalizing by n).
- Track training loss 0.5 ||X_bar w_t - y||^2 / n. It should decrease monotonically if η is properly chosen.
Step 6. Make predictions and assess
- Prediction for a new house: standardize its features using μ and σ, then compute y_hat = b + w1 x1_std + w2 x2_std.
- Assess fit by R^2, residual plots, or cross-validated error. Examine residuals for structure; if residuals grow with size, consider transforming y (e.g., log) or adding interactions.
Add interactions with linear algebra:
- Create a new feature x3 = x1_std * x2_std to capture the idea that the effect of size may depend on age.
- The pipeline remains the same: expand X, refit with least squares or regularization.
What you learn from the algebra:
- Scaling and orthogonality: Orthogonal features reduce parameter coupling and improve interpretability.
- Projection view: Predictions are projections of y onto the span of columns of X_bar. Adding features enlarges that span; regularization prevents overfitting by shrinking the projection.
Comparing L1 and L2 regularization in practice

Suppose you engineer 100 features, many of which are redundant. Which penalty should you use?
- Ridge (L2): Adds λ ||w||_2^2. Tends to keep all coefficients small but nonzero. Works well when many weakly relevant features share signal.
- Lasso (L1): Adds λ ||w||_1. Sets some coefficients exactly to zero, performing feature selection. However, among correlated features, it may arbitrarily pick one.
- Elastic net: λ1 ||w||_1 + λ2 ||w||_2^2. Balances sparsity and stability among correlated predictors.
Concrete effect on singular values:
- Ridge effectively adds λ to each eigenvalue of X^T X, so directions with tiny variance are no longer amplified.
- Lasso does not have a closed-form solution, but coordinate descent exploits separable soft-thresholding; each weight undergoes shrinkage toward zero with a threshold proportional to λ.
Actionable advice:
- Start with ridge if you care about predictive accuracy and stability and have many correlated features.
- Use lasso if you need interpretability through sparsity or when you suspect only a few features matter.
- Always scale features first; penalties are not comparable across features with different units.
How linear algebra appears in deep networks

Even the most complex networks are built from familiar blocks.
- Affine transforms: At each layer, compute Z = X W + b. Shapes matter: If X is (n, d), W is (d, k), Z is (n, k). Broadcast b of shape (k,) across rows.
- Nonlinearities: Apply elementwise f(Z) such as ReLU, GELU, or sigmoid. These preserve shapes and allow compositions to represent nonlinear functions.
- Convolutions: Can be seen as matrix multiplications after an im2col transform. Filters are small weight matrices applied across the input; linear algebra libraries power the ops.
- Attention: Scores are Q K^T / sqrt(d_k) with softmax over keys, followed by a weighted sum with V. This is dot products, scaling, and batched matrix multiplies with careful normalization for stability.
Gradient flow and spectra:
- To avoid vanishing or exploding gradients, initialize weights so that singular values of layer Jacobians cluster near 1. Orthogonal initialization and normalization layers help.
- Residual connections add the identity map, which keeps singular values closer to 1 and eases optimization.
Common pitfalls and how to fix them with algebraic insight
-
Pitfall: Features on wildly different scales. Symptom: oscillating or diverging gradient descent, ridge parameter hard to tune. Fix: Standardize features; consider whitening.
-
Pitfall: Perfect multicollinearity (one feature is a linear combination of others). Symptom: X^T X singular, coefficients blow up. Fix: Remove redundant features, use ridge, or switch to QR or SVD-based solvers.
-
Pitfall: Naive softmax computing exp of large numbers. Symptom: inf or NaN during training. Fix: Subtract rowwise maximum before exponentiation; use log-sum-exp.
-
Pitfall: Shape mismatches in backprop. Symptom: silent broadcasting mistakes leading to wrong gradients. Fix: Annotate shapes; use assert statements. In PyTorch, run with anomaly detection when debugging.
-
Pitfall: Overfitting with high-degree polynomial features. Symptom: near-zero training error, poor test performance. Fix: Increase regularization, reduce feature degree, or use cross-validation to select model complexity.
Where to go next and how to practice

You learn linear algebra for ML fastest by applying it in small, focused projects. Here is a progression that builds intuition and technical skill.
- Implement least squares three ways: normal equations, QR, and SVD. Compare coefficients and residuals on a dataset with correlated features. Observe how solutions differ when you add noise.
- Build logistic regression from scratch: vectorize the forward pass, derive the gradient, and implement batch gradient descent with a line search. Verify gradients with finite differences.
- Explore PCA end to end: center features, compute SVD, project onto k components, and reconstruct. Plot variance explained and visualize performance on a denoising task.
- Try kernel ridge regression on a small nonlinear dataset. Compare the RBF kernel against polynomial kernels. Time the fits as you scale n to see where approximations become necessary.
- For a tiny neural net on tabular data, inspect singular values of weight matrices during training. Experiment with orthogonal initialization and residual connections; watch how training speed and stability change.
As you practice, keep your algebraic toolkit handy: dot products for similarity, norms for error and regularization, projections for fitting, eigen and singular values for structure and stability, and Jacobians for gradients. When a model misbehaves, the fix is often a linear algebra move: rescale, rotate, project, regularize, or re-express your computation into a better-conditioned form.
Once you can see the underlying matrix operations, the black box disappears. Your models become predictable, your debugging faster, and your intuition sharper. Linear algebra is not just background theory; it is the way you drive machine learning with confidence.
Science Education Machine Learning Data Science Mathematics Mathematics & Statistics Linear Algebra Vectors and Matrices Eigenvalues and Eigenvectors Singular Value Decomposition (SVD) Principal Component Analysis (PCA) Gradient Descent Backpropagation Regularization Spectral Clustering Recommender Systems
Rate the Post
User Reviews







Popular Posts









